Classification of Romance languages
The internal classification of the Romance languages is a complex and sometimes controversial topic which may not have one single answer. Several classifications have been proposed, based on different criteria.
| Romance | |
|---|---|
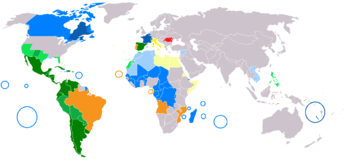
| Geographic distribution: |
|
| Linguistic classification: |
|
| Subdivisions: | |
| Glottolog: | roma1334[1] |
Variation among languages
In spite of their common origin, the descendants of Vulgar Latin have many differences. These occur at all levels, including the sound systems, the orthography, the nominal, verbal, and adjectival inflections, the auxiliary verbs and the semantics of verbal tenses, the function words, the rules for subordinate clauses, and, especially, in their vocabularies. While most of those differences are clearly due to independent development after the breakup of the Roman Empire (including invasions and cultural exchanges), one must also consider the influence of prior languages in territories of Latin Europe that fell under Roman rule, and possible heterogeneity in Vulgar Latin itself.
Romanian, together with other related languages, like Aromanian, has a number of grammatical features which are unique within Romance, but are shared with other non-Romance languages of the Balkans, such as Albanian, Bulgarian, Greek, Macedonian, Serbo-Croatian, Slovene and Turkish. These include, for example, the structure of the vestigial case system, the placement of articles as suffixes of the nouns (cer = "sky", cerul = "the sky"), and several more. This phenomenon, called the Balkan language area, may be due to contacts between those languages in post-Roman times.
Formation of plurals
Some Romance languages form plurals by adding /s/ (derived from the plural of the Latin accusative case), while others form the plural by changing the final vowel (by influence of Latin nominative plural endings, such as /i/) from some masculine nouns.
- Plural in /s/: Portuguese, Galician, Spanish, Catalan, Occitan, Sardinian, Friulian, Romansh.
- Vowel change: Italian, Romanian.
- Special case of French: Falls into the first group historically (and orthographically), but the final -s is no longer pronounced (except in liaison contexts), meaning that singular and plural nouns are usually homophonous in isolation. Many determiners have a distinct plural formed by both changing the vowel and allowing /z/ in liaison.
Words for "more"
Some Romance languages use a version of Latin plus, others a version of magis.
- Plus-derived: French plus /plys/, Italian più /pju/, Sardinian prus /ˈpruzu/, Piedmontese pi, Lombard pu, Ligurian ciù, Friulian plui, Romansh pli, Venetian pi. In Catalan pus /pus/ is exclusively used on negative statements in Mallorcan Catalan dialect, and "més" is the word mostly used.
- Magis-derived: Galician and Portuguese (mais; medieval Galician-Portuguese had both words: mais and chus), Spanish (más), Catalan (més), Venetian (massa or masa, "too much") Occitan (mai), Romanian (mai).
Words for "nothing"
Although the Classical Latin word for "nothing" is nihil, the common word for "nothing" became nulla in Italian (from neuter plural nulla, "no thing",[2] or from nulla res;[3] Italian also has the word "niente") nudda /nuɖːa/ in Sardinian, nada in Spanish, Portuguese, and Galician (from (rem) natam, "thing born";[4] Galician also has the word "ren"), rien in French, res in Catalan, cosa and res in Aragonese, ren in Occitan (from rem, "thing",[5] or else from nominative res),[6] nimic in Romanian, nagut in Romansh, gnente in Venetian and Piedmontese, gnent and nagott in Lombard, and nue and nuie in Friulian. Some argue that most roots derive from different parts of a Latin phrase nullam rem natam ("no thing born"), an emphatic idiom for "nothing". Meanwhile, Italian and Venetian niente and gnente would seem to be more logically derived from Latin ne(c) entem ("no being"), ne inde or, more likely, ne(c) (g)entem, which also explains the French cognate word néant.[7][8] The Piedmontese negative adverb nen cames also directly from ne(c) (g)entem,[3] while gnente is borrowed from Italian.
The number 16
Romanian constructs the names of the numbers 11–19 by a regular Slavic-influenced pattern that could be translated as "one-over-ten", "two-over-ten", etc. All the other Romance languages use a pattern like "one-ten", "two-ten", etc. for 11–15, and the pattern "ten-and-seven, "ten-and-eight", "ten-and-nine" for 17–19. For 16, however, they split into two groups: some use "six-ten", some use "ten-and-six":
- "Sixteen": Italian sedici, Catalan and Occitan setze, French seize, Venetian sédexe, Romansh sedesch, Friulian sedis, Lombard sedas / sedes, Franco-Provençal sèze, Sardinian sèighi, Piedmontese sëddes (sëddes is borrowed from Lombard and substituted the original sëzze since the 18th century).
- "Ten and six": Portuguese dezasseis or dezesseis, Galician dezaseis (decem ac sex), Spanish dieciséis (romance construction: diez y seis), the Marchigiano dialect digissei.
- "Six over ten": Romanian șaisprezece (where spre derives from Latin super).
Classical Latin uses the "one-ten" pattern for 11–17 (ūndecim, duodecim, ..., septendecim), but then switches to "two-off-twenty" (duodēvigintī) and "one-off-twenty" (ūndēvigintī). For the sake of comparison, note that English and German use two special words derived from "one left over" and "two left over" for 11 and 12, then the pattern "three-ten", "four-ten", ..., "nine-ten" for 13–19.
To have and to hold
The verbs derived from Latin habēre "to have", tenēre "to hold", and esse "to be" are used differently in the various Romance languages, to express possession, to construct perfect tenses, and to make existential statements ("there is"). If we use T for tenēre, H for habēre, and E for esse, we have the following distribution:
- HHE: Romanian, Italian, Gallo-Italic languages.
- HHH: Occitan, French, Romansh, Sardinian.
- THH: Spanish, Catalan, Aragonese.
- TTH: European Portuguese.
- TTT: Brazilian Portuguese. (colloquial)
For example:
| Language | Possessive predicate | Perfect | Existential | Pattern |
|---|---|---|---|---|
| English | I have | I have done | There is | HHE |
| Italian | (io) ho | (io) ho fatto | c'è | HHE |
| Friulian | (jo) o ai | (jo) o ai fat | a 'nd è, al è | HHE |
| Venetian | (mi) go | (mi) go fat | ghe xe, ghi n'é | HHE |
| Lombard (Western) | (mi) a gh-u | (mi) a u fai | al gh'è, a gh'è | HHE |
| Piedmontese | (mi) i l'hai | (mi) i l'hai fàit | a-i é | HHE |
| Romanian | (eu) am | (eu) am făcut | este / e | HHE |
| Sardinian | (deo) apo | (deo) apo fattu | bi at / bi est | HHH |
| Romansh | (jau) hai | (jau) hai fatg | igl ha | HHH |
| French | j'ai | j'ai fait | il y a | HHH |
| Catalan | (jo) tinc | (jo) he fet | hi ha | THH |
| Aragonese | (yo) tiengo (yo) he (dialectally) | (yo) he feito | bi ha | THH |
| Spanish | (yo) tengo | (yo) he hecho | hay | THH |
| Galician | (eu) teño | — [no present perfect] | hai | T–H |
| Portuguese (Portugal) | (eu) tenho | (eu) tenho feito | há | TTH |
| Portuguese (Brazil) | (eu) tenho | (eu) tenho feito | tem | TTT |
Ancient Galician-Portuguese used to employ the auxiliary H for permanent states, such as Eu hei um nome "I have a name" (i.e. for all my life), and T for non-permanent states Eu tenho um livro "I have a book" (i.e. perhaps not so tomorrow), but this construction is no longer used in modern Galician and Portuguese. Informal Brazilian Portuguese uses the T verb even in the existential sense, e.g. Tem água no copo "There is water in the glass".
Languages that have not grammaticalised *tenēre have kept it with its original sense "hold", e.g. Italian tieni il libro, French tu tiens le livre, Romanian ține cartea, Friulian Tu tu tegnis il libri "You're holding the book". The meaning of "hold" is also retained to some extent in Spanish and Catalan.
Romansh uses, besides igl ha, the form i dat (literally: it gives), calqued from German es gibt.
To have or to be
Some languages use their equivalent of 'have' as an auxiliary verb to form the compound forms (e. g. French passé composé) of all verbs; others use 'be' for some verbs and 'have' for others.
- 'have' only: Standard Catalan, Spanish, Romanian, Sicilian.
- 'have' and 'be': Occitan, French, Italian, Northern-Italian languages (Piedmontese, Lombard, Ligurian, Venetian, Friulan), Romansh, Central Italian languages (Tuscan, Umbrian) some dialects of Catalan (although such usage is recessing in those).
In the latter type, the verbs which use 'be' as an auxiliary are unaccusative verbs, that is, intransitive verbs that often show motion not directly initiated by the subject or changes of state, such as 'fall', 'come', 'become'. All other verbs (intransitive unergative verbs and all transitive verbs) use 'have'. For example, in French, J'ai vu or Italian ho visto 'I have seen' vs. Je suis tombé, sono caduto 'I have (lit. am) fallen'. Note, however, the difference between French and Italian in the choice of auxiliary for the verb 'be' itself: Fr. J'ai été 'I have been' with 'have', but Italian sono stato with 'be'. In Southern Italian languages the principles governing auxiliaries can be quite complex, including even differences in persons of the subject. A similar distinction exists in the Germanic languages, which share a language area; German and the Scandinavian languages use 'have' and 'be', while modern English now uses 'have' only (although 'be' remains in certain relic phrases: Christ is risen, Joy to the world: the Lord is come).
"Be" is also used for reflexive forms of the verbs, as in French j'ai lavé 'I washed [something]', but je me suis lavé 'I washed myself', Italian ho lavato 'I washed [something]' vs. mi sono lavato 'I washed myself'.
Classification
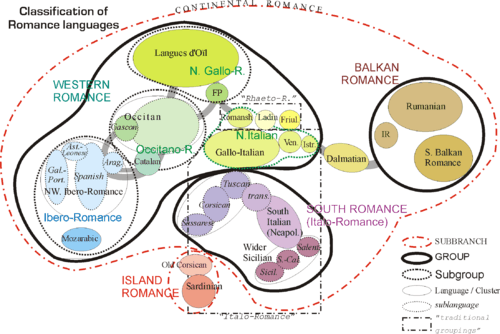
Difficulties of classification
The comparative method used by linguists to build family language trees is based on the assumption that the member languages evolved from a single proto-language by a sequence of binary splits, separated by many centuries. With that hypothesis, and the glottochronological assumption that the degree of linguistic change is roughly proportional to elapsed time, the sequence of splits can be deduced by measuring the differences between the members.
However, the history of Romance languages, as we know it, makes the first assumption rather problematic. While the Roman Empire lasted, its educational policies and the natural mobility of its soldiers and administrative officials probably ensured some degree of linguistic homogeneity throughout its territory. Even if there were differences between the Vulgar Latin spoken in different regions, it is doubtful whether there were any sharp boundaries between the various dialects. On the other hand, after the Empire's collapse, the population of Latin speakers was separated—almost instantaneously, by the standards of historical linguistics—into a large number of politically independent states and feudal domains whose populations were largely bound to the land. These units then interacted, merged and split in various ways over the next fifteen centuries, possibly influenced by languages external to the family (as in the so-called Balkan language area).
To sum it up, the history of Latin and Romance-speaking peoples can hardly be described by a binary branching pattern; therefore, one may argue that any attempt to fit the Romance languages into a tree structure is inherently flawed.[9] In this regard, the genealogical structure of languages forms a typical linkage.[10]
On the other hand, the tree structure may be meaningfully applied to any subfamilies of Romance whose members did diverge from a common ancestor by binary splits. That may be the case, for example, of the dialects of Spanish and Portuguese spoken in different countries, or the regional variants of spoken standard Italian (but not the so-called "Italian dialects", which are distinct languages evolved directly from Vulgar Latin).
The standard proposal
Nevertheless, by applying the comparative method, some linguists have concluded that the earliest split in the Romance family tree was between Sardinian and the remaining group, called Continental Romance. Among the many peculiar Sardinian distinguishing features are its articles (derived from Latin IPSE instead of ILLE) and retention of the "hard" sounds of "c" and "g" before "e" and "i".
According to this view, the next split was between Romanian in the east, and the other languages (the Italo-Western languages) in the west. One of the characteristic features of Romanian is its retention of three of Latin's seven noun cases. The third major split was more evenly divided, between the Italian branch, which comprises many languages spoken in the Italian Peninsula, and the Gallo-Iberian branch.
Another proposal
However, this is not the only view. Another common classification begins by splitting the Romance languages into two main branches, East and West. The East group includes Romanian, the languages of Corsica and Sardinia, and all languages of Italy south of a line through the cities of Rimini and La Spezia (see La Spezia–Rimini Line). Languages in this group are said to be more conservative, i.e. they retained more features of the original Latin.
The latter then split into a Gallo-Romance group, which became the Oïl languages (including French), Gallo-Italian, Occitan, Franco-Provençal and Romansh, and an Iberian Romance group which became Spanish and Portuguese. Catalan is considered by many specialists as a transition language between the Gallic group and the Iberian group, since it shares characteristics from both groups; for example, "fear" is medo/pavor/temor in Portuguese, miedo/pavor/temor in Spanish, (from metus, pavore and timor), in Catalan por/paüra/temor; but peur/crainte in French and paura in Italian.
The wave hypothesis
Other linguists claim that the various regional languages did not evolve in isolation from their neighbours; on the contrary, they see many changes propagating from the more central regions (Italy and France) towards the periphery (Iberian Peninsula and Romania).
Degree of separation from Latin
In a study by linguist Mario Pei (1949), the degrees of evolution of the Romance languages with respect to the ancestral Latin were found to be as follows[11][12]
- Sardinian: 8%;
- Italian: 12%;
- Spanish: 20%;
- Romanian: 23.5%;
- Occitan: 25%;
- Portuguese: 31%;
- French: 44%.
References
- François, Alexandre (2014), "Trees, Waves and Linkages: Models of Language Diversification" (PDF), in Bowern, Claire; Evans, Bethwyn, The Routledge Handbook of Historical Linguistics, London: Routledge, pp. 161–189, ISBN 978-0-41552-789-7.
- Italica: Bulletin of the American Association of Teachers of Italian. 27–29. Menasha, Wisconsin: George Banta Publishing Company. 1950. Retrieved November 18, 2013.
- Koutna, Olga (December 31, 1990). "Chapter V. Renaissance: On the History of Classifications in the Romance Language Group". In Niederehe, Hans-Josef; Koerner, E.F.K. History and Historiography of Linguistics: Proceedings of the Fourth International Conference on the History of the Language Sciences (ICHoLS IV), Trier, 24–28 August 1987. Volume 1: Antiquitity–17th Century. Amsterdam, The Netherlands / Philadelphia, PA: John Benjamins Publishing Company. p. 294. ISBN 9027278113. Retrieved November 18, 2013.
- Penny, Ralph (2000). Variation and Change in Spanish. Cambridge University Press. ISBN 0-521-78045-4.
Notes
- ↑ Hammarström, Harald; Forkel, Robert; Haspelmath, Martin; Bank, Sebastian, eds. (2016). "Romance". Glottolog 2.7. Jena: Max Planck Institute for the Science of Human History.
- ↑ Entry nulla in Vocabolario Treccani (Italian)
- 1 2 R. Zanuttini, Negazione e concordanza negativa in italiano e in piemontese (Italian)
- ↑ Entry nada in Diccionario de la lengua española (Spanish)
- ↑ Entry rien in CNTRL (French)
- ↑ Entry res in diccionari.cat (Catalan)
- ↑ Entry niente in Vocabolario Treccani (Italian)
- ↑ Entry néant in CNRTL (French)
- ↑ “Not only is the tree model inadequate to express the relationships between diatopically related varieties, but it may seriously distort the diachronic and synchronic study of language. Some would argue that this model works well within Indo-European linguistics, where the varieties under consideration (all written and therefore partially or fully standardized) are usually well separated in space and time and where the intervening varieties have all vanished without trace, removing any possibility of viewing the Indo-European family as a continuum. However, where the object of study is a series of now-existing varieties or a range of closely related varieties from the past, the tree model is open to a number of grave objections.” (Penny 2000: 22).
- ↑ “A linkage consists of separate modern languages which are all related and linked together by intersecting layers of innovations; it is a language family whose internal genealogy cannot be represented by any tree.” (François 2014:171).
- ↑ See Italica 1950: 46 (cf. and ): “Pei, Mario A. "A New Methodology for Romance Classification." Word, v, 2 (Aug. 1949), 135–146. Demonstrates a comparative statistical method for determining the extent of change from the Latin for the free and checked accented vowels of French, Spanish, Italian, Portuguese, Rumanian, Old Provençal, and Logudorese Sardinian. By assigning 3½ change points per vowel (with 2 points for diphthongization, 1 point for modification in vowel quantity, ½ point for changes due to nasalization, palatalization or umlaut, and −½ point for failure to effect a normal change), there is a maximum of 77 change points for free and checked stressed vowel sounds (11×2×3½=77). According to this system (illustrated by seven charts at the end of the article), the percentage of change is greatest in French (44%) and least in Italian (12%) and Sardinian (8%). Prof. Pei suggests that this statistical method be extended not only to all other phonological, but also to all morphological and syntactical, phenomena.”.
- ↑ See Koutna et al. (1990: 294): “In the late forties and in the fifties some new proposals for classification of the Romance languages appeared. A statistical method attempting to evaluate the evidence quantitatively was developed in order to provide not only a classification, but at the same time a measure of the divergence among the languages. The earliest attempt was made in 1949 by Mario Pei (1901–1978), who measured the divergence of seven modern Romance languages from Classical Latin, taking as his criterion the evolution of stressed vowels. Pei's results do not show the degree of contemporary divergence among the languages from each other but only the divergence of each one from Classical Latin. The closest language turned out to be Sardinian with 8% of change. Then followed Italian — 12%; Spanish — 20%; Romanian — 23,5%; Provençal — 25%; Portuguese — 31%; French — 44%.”