SW26010
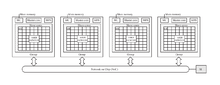
The SW26010 is a 260-core manycore processor designed by the National High Performance Integrated Circuit Design Center in Shanghai. It implements the Sunway architecture, a 64-bit reduced instruction set computing (RISC) architecture designed by China.[1] The SW26010 has four clusters of 64 Compute-Processing Elements (CPEs) which are arranged in an eight-by-eight array. The CPEs support SIMD instructions, and are capable of performing eight double-precision floating-point operations per cycle. Each cluster is accompanied by a more conventional general-purpose core called the Management Processing Element (MPE) that provides supervisory functions.[1] Each cluster has its own dedicated DDR3 SDRAM controller, and a memory bank with its own address space.[2][3] The processor runs at a clock speed of 1.45 GHz.[4] It is fabricated using 28nm process technology.
The CPE cores feature 64 KB of scratchpad memory for data and 16 KB for instructions, and communicate via a network on a chip, instead of having a traditional cache hierarchy.[5] The MPE's have a more traditional setup, with 32 KB L1 instruction and data caches and a 256 KB L2 cache.[1] Finally, the on-chip network connects to a single system interconnection interface that connects the chip to the outside world.
The SW26010 is used in the Sunway TaihuLight supercomputer, which as of November 2016, is the world's fastest supercomputer as ranked by the TOP500 project.[6] The system uses 40,960 SW26010s to obtain 93.01 PFLOPS on the LINPACK benchmark.
See also
- Massively parallel processor array
- Loongson, another home-grown Chinese architecture
- Adapteva
- Cell (microprocessor)
References
- 1 2 3 Dongarra, Jack (June 20, 2016). "Report on the Sunway TaihuLight System" (PDF). www.netlib.org. Retrieved June 20, 2016.
- ↑ Fu, H H; Liao, JF; Yang, J Z (2016). "The Sunway TaihuLight Supercomputer: System and Applications". Sci. China Inf. Sci. doi:10.1007/s11432-016-5588-7. Retrieved 2016-06-22.
- ↑ Trader, Tiffany (June 19, 2016). "China Debuts 93-Petaflops 'Sunway' with Homegrown Processors". HPC Wire. Retrieved 21 June 2016.
Each core of the CPE has a single floating point pipeline that can perform 8 flops per cycle per core (64-bit floating point arithmetic) and the MPE has a dual pipeline each of which can perform 8 flops per cycle per pipeline (64-bit floating point arithmetic).
- ↑ Hemsoth, Nicole (2016-06-20). "A Look Inside China's Chart-Topping New Supercomputer". The Next Platform. Retrieved 2016-06-20.
- ↑ Lendino, Jamie (20 June 2016). "Meet the new world's fastest supercomputer: China's TaihuLight". Extremetech. Retrieved 21 June 2016.
The TOP500 report said that the chip also lacks any traditional L1-L2-L3 cache, and instead has 12KB of instruction cache and 64KB “local scratchpad” that works sort of like an L1 cache.
- ↑ "Top 500 The List: November 2016". TOP 500. 14 November 2016. Retrieved 26 November 2016.